
Hibernate API
1. Configuration 类
Configuration类用来管理配置文件信息,我们可以创建一个configuration实例来管理相应的配置文档,但是通常只创建一个configuration实例。
Configuration 加载配置文件的方式:
- xml作为配置文件
- properties作为配置文件
- 不使用配置文件
1. configure() 方法
用来在加载xml配置文件
Configuration conf =new Configuration();
conf.configure("xxx.xml");
如果配置文件是规范的命名 hibernate.cfg.xml,则可以写成
conf.configure();
2. addResource() 方法
此方法用来硬加载映射配置文件。在主配置文件中没有使用<mapping resource="xxx.hbm.xml"/>加载映射文件,可使用conf.addResource("xxx.hbm.xml");来硬加载映射配置文件。
3. buildSessionFactory() 方法
此方法用来得到SessionFactory对象。
SessionFactory sessions = conf.buildSessionFactory();
SessionFactory接口负责初始化Hibernate。它充当数据存储源的代理,并负责创建Session对象。
SessionFactory是线程安全的,可以被多个线程调用。需要注意的是SessionFactory并不是轻量级的,因此,一般情况下,一个项目通常只需要一个SessionFactory就够。当需要操作多个数据库时,可以为每个数据库指定一个SessionFactory。
2. Session 类
Session 是用来表示,应用程序和数据库的一次交互(会话)。在Session中,包含了一般的对象持久化方法(CRUD)。
Session是一个轻量级对象(线程不安全),通常将每个Session实例和一个数据库事务绑定,也就是每执行一个数据库事务,都应该先创建一个新的Session实例,在使用Session后,还需要关闭Session。
1. openSession() 方法和 getCurrentSession() 方法的联系和区别
相同:
openSession() 方法和 getCurrentSession() 方法都可以得到Session对象
区别:
- getCurrentSession()创建的Session会绑定到当前的线程中去,而采用OpenSession()则不会。
- getCurrentSession()创建的Session会在事务commit或rollback后会自动关闭,采用OpenSession()必须手动关闭。
- getCurrentSession()需要在Hibernate.cfg.xml配置文件中加入相关配置。
getCurrentSession() 相关配置:
- 如果是本地事务,及JDBC一个数据库:
<propety name="Hibernate.current_session_context_class">thread</propety>
- 如果是全局事务,及jta事务、多个数据库资源或是事务资源:
<propety name="Hibernate.current_session_context_class">jta</propety>
注意:如果只使用Hibernate没有使用其它框架时,使用getCurrentSession()方法必须要手动开启事务,不然会抛异常!!!
2. Hibernate的对象标识符(OID)
Hibernate 使用对象标识符(OID)来标识对象的唯一性。OID是关系数据库中主键在Java对象模型中的等价物。
为了保证持久化对象的OID的唯一性和不可变性,通常由Hibernate或底层数据库来给OID赋值。因此,可以把OID的set方法设为private类型,get方法设为public类型,这使得Java应用程序可以读取持久化对象的OID,但禁止了Java应用程序对OID的修改。
3. Hibernate对象的四种状态
状态是对对象所处情境的描述,在对hibernate定义了几种状态之后即方便了为人所达成共识,同时也能更好的理解hibernate的工作机制。
对象的四种状态:
-
瞬时态(Transient):
也称为临时态或自由态。创建Session后,由
new操作符创建的对象,且不在Session的缓存中的状态。数据库记录没有,也没有OID。如果瞬时对象在程序中没有被引用,它会被垃圾回收器销毁。 -
持久态(Persistent):
对象被持久化了,存在于Session缓存中的状态。数据库记录有,OID也有。Hibernate会检测到处于持久状态的对象的任何改动,在当前操作单元(unit of work)执行完毕时将对象数据(state)与数据库同步,开发者不需要手动执行UPDATE。
-
游离态(Detached):
也称为脱管态。对象持久化后,Session关闭了,或执行了evict()方法,亦或执行了clear()方法的状态。不在Session缓存之中,但数据库记录有,也有OID。游离态对象不能直接持久化,需要重新保存。
-
删除态(Deleted):
调用Session的delete()方法之后,对象就变成删除态。Session缓存中仍然有对象的信息,对删除态对象的引用依然有效,对象可继续被修改。数据库记录没有,OID还在。删除态对象如果重新关联到某个新的Session上,会重新持久化。
对象的四种状态图示:
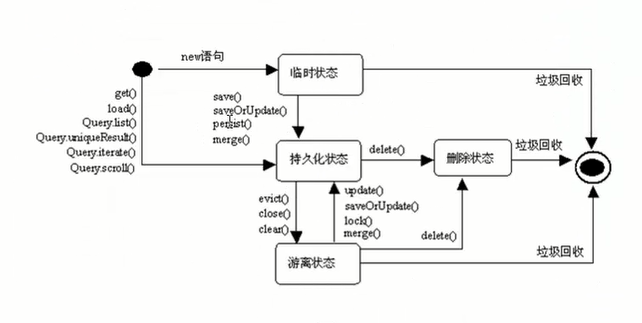
其它状态对象持久化操作:
- 持久态时,则基本上什么也不需要做。
- 瞬时态时,则如需对其持久化,执行save/saveOrUpdate/persist操作。
- 删除态时,则如需对其持久化,执行persist操作。
- 游离态时,则需要执行update/saveOrUpdate操作。
注意:当实体类的主键生成策略为assigned时,临时态和游离态等同!!!
4. get() 方法和 load() 方法
相同:
get(Class c,OID) 方法和 load(Class c,OID) 方法都是根据主键查询,返回一个持久态对象。
区别:
-
get()返回的是查询出来的实体对象,而load()查询出来的是一个目标实体的代理对象。
-
get()在调用的时候首先查找Session一级缓存,然后查找二级缓存,然后再发出SQL语句查询; 而load()首先查找Session一级缓存,然后查找二级缓存,若找不到则返回代理对象,延迟到真正使用对象非主键属性时才发出sql语句并且将被代理对象属性
target填充上,但是如果这个动作发生在Session被关闭后的话就会抛出LazyInitializationException。 -
当查询结果为空时,get()抛出
NullPointerException异常;load()抛出ObjectNotFoundException异常。
5. save() 方法和 persist() 方法
相同:
save(Object o) 方法和 persist(Object o) 方法都可以把一个临时态对象持久化,保存到数据库里,插入一条新记录。
区别:
-
persist()把一个临时态的对象持久化时,“不保证”OID被立刻填入到持久化实例的主键中,标识符的填入可能被推迟到flush的时间。
-
persist()无返回值,当它在一个事务外部被调用的时候并不向数据库发送
INSERTSQL语句;save()返回持久化对象的OID,所以它会立即向数据库发送INSERTSQL语句,不管是不是在事务内部还是外部
6. update() 方法
update(Object o)把一个游离态对象持久化,修改一条主键与OID相对应的记录,无返回值。
7. saveOrUpdate() 方法
saveOrUpdate(Object o)方法同时包含了save(Object o)与update(Object o)方法的功能。如果:
- 参数是临时态对象,就调用save()方法;
- 参数是游离态对象,就调用update()方法;
- 参数是持久态对象,那就直接返回。
- 参数的OID与本session关联的对象的OID相同,则抛出一个异常
那么,saveOrUpdate()方法如何判断一个对象处于临时状态还是游离状态呢?如果满足以下情况之一,Hibernate就把它作为临时对象。
- Java对象的OID取值为
null。 - Java对象具有
version属性并且取值为null。 - 对象映射文件中设置了
unsaved-value属性,并且OID取值与unsaved-value属性值匹配。 - 在对象映射文件中为
version属性设置了unsaved-value属性,并且version属性取值与unsaved-value属性值匹配。 - 自定义了Hibernate的Interceptor实现类,并且Interceptor的
isUnsaved()方法返回Boolean.TRUE。
8. merge() 方法
hibernate中,是不允许出现相同的OID对象有两个不同session同时关联的情况,不然会抛出异常,可以使用merge(Object object)这个方法来解决这一问题。
-
参数是临时态对象时,merge()会保存数据,根据主键生成策略插入一条新记录;
-
参数是游离态时对象(对象A)时,如果不存在与之OID对应的主键的记录,则插入一条新记录;
如果存在与之OID相对应的主键的记录,则根据主键从数据库中加载出该对象(对象B),然后将参数object(对象A)中的属性拷贝到加载出来的那个对象上(对象B),最后返回该持久化对象(对象B),同时数据库里的记录的变更成参数object(对象A)的数据。注意,对象B是持久态,但是参数object(对象A)还是游离态!
-
如果Session中存在与参数objcet(对象A)具有相同OID属性的对象(对象B),那么直接将参数object(对象A)中的属性拷贝到该持久化对象上(对象B),然后返回该持久化对象(对象B),同时数据库里的记录的变更成参数object(对象A)的数据。注意,对象B是持久态,但是参数object(对象A)还是游离态!
9. delete() 方法
delete(Object o)把一个持久态对象从Session中删除,转变为删除态对象,同时删除数据库里一条记录。
3. Query 接口
Query是Hibernate的查询接口,用于从数据存储源查询对象及控制执行查询的过程,Query包装了一个HQL查询语句。
Query对象在Session对象关闭之前有效,否则会抛出SessionException异常。因为Session对象就想JDBC中的Connection 对象,即数据库的一次连接。关闭Connection对象,Statement对象就不能再使用,所以关闭Session后就不能再使用Query对象了。
1. createQuery() 方法
createQuery(String hql)执行hql语句,得到Query对象。
1. set系列方法
setxxx() 用于设置HQL语句中问号或者变量的值;
设置HQL语句中问号或者变量的值有两种使用方式:
- 如:
setString(int position,String value),设置HQL中的"?"的值,其中position代表"?"在HQL中的位置,value是要为"?"设置的值。 - 如:
setString(String paraName,String value),设置":"后跟变量的值,其中paraName代表HQL中":"后的变量名,value是该变量的值。
2. uniqueResult() 方法、
query.uniqueResult() 返回查询结果,得到一个对象。
3. list() 方法
query.list() 返回查询结果,得到一个List对象
4. setFirstResult() 方法和 setMaxResults() 方法
query.setFirstResult(int rowNum) 用于设置数据库起始查询行号;
query.setMaxResults(int pageSize) 用于设置结果集每页的条数;
这两个方法用于实现分页查询。
4. Session 缓存方法
Hibernate中提供了两级缓存,一级缓存是Session级别的缓存,它属于事务范围的缓存,该级缓存由hibernate管理,应用程序无需干预;二级缓存是SessionFactory级别的缓存,该级缓存可以进行配置和更改,并且可以动态加载和卸载,hibernate还为查询结果提供了一个查询缓存,它依赖于二级缓存。
1. evict() 方法
evict(Object o) 作用是将session一级缓存中的指定的对象清除,将对象状态由持久态转换为游离态。
2. clear() 方法
clear() 作用是将session一级缓存中的所有对象全部清除,将对象状态由持久态转换为游离态。
3. flush() 方法
flush() 将session缓存中的数据推出到数据库,立即执行sql语句,但是不会提交事务。
4. refresh() 方法
refresh() 会强制发送SELECTSQL语句,使数据库表中的记录更新到Session缓存的对象中。该方法的有效性与事务隔离级别有关,需要配置事务的隔离级别为read commited(读已提交)。
5. close() 方法
close() 关闭当前的Session连接,清空Session缓存;如果事务没有开启,会在执行close() 之前调用一次flush(),强制数据同步到数据库。
5. Transaction 接口
Hibernate本身没有实现自己的事务管理功能,而是对底层JDBC事务或JTA事务的轻量级封装。
1. beginTransaction() 方法
beginTransaction()开启事务,也可以使用getTransaction().begin()开启;事务开启后会禁用自动提交,返回一个Transaction 对象。
2. getTransaction() 方法
getTransaction()返回一个 Transaction 对象。
3. commit() 方法
transaction.commit() 事务提交;
手动提交后会恢复事务自动提交。
4. rollback() 方法
transaction.rollback() 事务回滚
6. Criteria 接口
Criteria 是一个完全面向对象,可扩展的条件查询API,通过它完全不需要考虑数据库底层如何实现、SQL语句如何编写,是Hibernate框架的核心查询对象。
Criteria 接口用于QBC(Query By Criteria) 查询。
使用QBC查询,一般需要以下三个步骤:
- 使用Session实例 的
createCriteria()方法创建Criteria对象。(此方法在Hibernate 5.2 已被标记为过时) - 使用工具类Restrictions的方法为Criteria对象设置查询条件,Order工具类的方法设置排序方式,Projections工具类的方法进行统计和分组。
- 使用Criteria对象的
list()方法进行查询并返回结果。
1. DetachedCriteria 接口
Hibernate 设计了 CriteriaSpecification 作为 Criteria 的父接口,下面提供了 Criteria和DetachedCriteria。
Criteria 和 DetachedCriteria 的主要区别在于创建的形式不一样, Criteria 是在线的,是由 Session 进行创建;而 DetachedCriteria 是离线的,创建时无需Session。
DetachedCriteria 提供了 2 个静态方法 forClass(Class c) 或 forEntityName(String EntityName) 进行DetachedCriteria 实例的创建。
2. Restrictions 工具类
Criterion 是 Criteria 的查询条件。Criteria 提供了 add(Criterion criterion) 方法来添加查询条件。
Criterion 的实例可以通过 Restrictions 工具类来创建,Restrictions 提供了大量的静态方法来方法的创建 Criterion 查询条件
Restrictions的常用方法
方法名称 | 描述 | --|--| Restrictions.eq | 等于 Restrictions.allEq | 使用Map,Key/Valu进行多个等于的比对 Restrictions.gt | 大于 Restrictions.ge | 大于等于 Restrictions.lt | 小于 Restrictions.le | 小于等于 Restrictions.between | 对应SQL的between Restrictions.like | 对应SQL的like Restrictions.in | 对应SQL的in Restrictions.and | and关系 Restrictions.or | or关系 Restrictions.sqlRestriction | SQL限定查询
3. Order 工具类
Order类的常用方法:
方法名 | 称描述 | --|--| Order.asc | 升序 Order.desc | 降序
4. Projections 工具类
Projections类的常用方法:
方法名称 | 描述 | --|--| Projections.avg | 求平均值 Projections.count | 统计某属性的数量 Projections.countDistinct | 统计某属性不同值的数量 Projections.groupProperty | 指定某个属性为分组属性 Projections.max | 求最大值 Projections.min | 求最小值 Projections.projectionList | 创建一个ProjectionList对象 Projections.rowCount | 查询结果集中的记录条数 Projections.sum | 求某属性的合计
2. 映射配置文件
- 基于ORM思想实现实体类与数据表的映射
- OMR(Object Relation Mapping)
3. 主键生成策略
-
increment
设置为
increment时,Hibernate自己在维护主键的值。当插入新记录时,先从数据库中获取当前的主键的最大值,然后在最大值上加1,作为新的主键值用其生成的主键对应的OID的类型可以是
long,short,int及其包装类类型。此策略只能在没其他进程向同意张表中插入数据时才能使用,在高并发或集群下不能使用。 -
identity
此策略使用数据库自身增长来维护主键值,适用于MySQL、DB2、MS SQL Server。
此策略的主键值与数据插入的成功与否无关,即使最后事务回滚了,数据库中的主键字段的值也会加一。用此策略生成的主键对应的OID可以是
long、short、int及其包装类类型。 -
sequence
此策略造数据库中创建一个序列(sequence),然后 Hibernate 通过该序列为主键字段赋值,适用于 Oracle、DB2 和 PostgreSQL。
用此策略生成的主键对应的OID可以是
long、short、int及其包装类类型。 -
native
由 Hibernate 根据所使用的数据库支持能力从 identity、sequence 生成策略中选择一种。
使用此策略可以根据不同的数据库采用不同的生成策略,如 Oracle 中使用 sequence,在 MySQL中使用 identity便于 Hibernate 应用在不同的数据库之间移植。
-
uuid
次策略采用了 UUID 算法来生成一个字符串类型的主键值,该值使用 IP 地址、JVM 的启动时间(精确到 1/4秒)、系统时间和一个计数器值(在当前的 JVM中唯一)经过计算产生,可以用于分布式的 Hibernate 应用中。
产生的标识符是一个 32 位长度16进制的数字字符串,该值保证了在同一时空全网唯一。
-
assigned
此策略用于手动填写主键,Hibernate不自动生成
-
foreign
使用另外一个相关联的对象的主键作为该对象主键,主要用于一对一关系中。
3. Hibernate 注解
1. 类级别注解
-
@Entity映射实体类@Entity(name="tableName")- 必须,注解将一个类声明为一个实体bean。属性:name - 可选,对应数据库中的一个表。若表名与实体类名相同,则可以省略。
-
@Table映射数句库表@Table(name="",catalog="",schema="")- 可选,通常和@Entity 配合使用,只能标注在实体的 class 定义处,表示实体对应的数据库表的信息。属性:
- name - 可选,表示表的名称,默认地,表名和实体名称一致,只有在不一致的情况下才需要指定表名
- catalog - 可选,表示Catalog名称,默认为 Catalog("")。
- schema - 可选,表示 Schema 名称,默认为Schema("")。
2. 属性级别注解
1. 与主键相关注解
-
@Id- 必须,定义了映射到数据库表的主键的属性,一个实体只能有一个属性被映射为主键,置于 getXxxx() 前。 -
@GeneratedValue(strategy=GenerationType,generator="")- 可选,用于定义主键生成策略。属性:
-
strategy- 表示主键生成策略,取值有:GenerationType.AUTO- 根据底层数据库自动选择(默认),若数据库支持自动增长类型,则为自动增长。GenerationType.INDENTITY- 根据数据库的Identity字段生成,支持DB2、MySQL、MS、SQL Server、SyBase与HyperanoicSQL数据库的Identity类型主键。GenerationType.SEQUENCE- 使用Sequence来决定主键的取值,适合Oracle、DB2等支持Sequence的数据库,一般结合@SequenceGenerator使用。GenerationType.TABLE- 使用指定表来决定主键取值,结合@TableGenerator使用。
-
generator- 表示主键生成器的名称,这个属性通常和ORM框架相关 , 例如: Hibernate 可以指定 uuid 等主键生成方式
-
-
@SequenceGenerator— 注解声明了一个数据库序列。属性:
name- 表示该表主键生成策略名称,它被引用在@GeneratedValue中设置的gernerator值中。sequenceName- 表示生成策略用到的数据库序列名称。initialValue- 表示主键初始值,默认为0。allocationSize- 每次主键值增加的大小,例如设置成1,则表示每次创建新记录后自动加1,默认为50。
2.与非主键相关注解
-
@Version- 可以在实体bean中使用@Version注解,通过这种方式可添加对乐观锁定的支持 -
@Basic- 用于声明属性的存取策略:@Basic(fetch=FetchType.EAGER)即时获取(默认)@Basic(fetch=FetchType.LAZY)延迟获取
-
@Temporal- 用于定义映射到数据库的时间精度:@Temporal(TemporalType=DATE)日期@Temporal(TemporalType=TIME)时间@Temporal(TemporalType=TIMESTAMP)两者兼具
-
@Column- 可将属性映射到列,使用该注解来覆盖默认值,@Column描述了数据库表中该字段的详细定义,这对于根据 JPA 注解生成数据库表结构的工具非常有作用。属性:
name- 可选,表示数据库表中该字段的名称,默认情形属性名称一致。nullable-可选,表示该字段是否允许为 null,默认为true。unique- 可选,表示该字段是否是唯一标识,默认为false。length- 可选,表示该字段的大小,仅对 String 类型的字段有效,默认值255。insertable-可选,表示在ORM框架执行插入操作时,该字段是否应出现INSETRT语句中,默认为true。updateable-可选,表示在ORM 框架执行更新操作时,该字段是否应该出现在UPDATE语句中,默认为true。对于一经创建就不可以更改的字段,该属性非常有用,如对于 birthday 字段。columnDefinition- 可选,表示该字段在数据库中的实际类型。通常ORM框架可以根据属性类型自动判断数据库中字段的类型,但是对于Date类型仍无法确定数据库中字段类型究竟是 DATE , TIME 还是 TIMESTAMP. 此外,String 的默认映射类型为VARCHAR, 如果要将 String 类型映射到特定数据库的 BLOB 或 TEXT字段类型,该属性非常有用。
-
@Transient- 可选,表示该属性并非一个到数据库表的字段的映射,ORM框架将忽略该属性,如果一个属性并非数据库表的字段映射,就务必将其标示为@Transient,否则ORM 框架默认其注解为@Basic
3. 无注解属性的默认值
如果属性为单一类型,则映射为@Basic,
否则,如果属性对应的类型定义了@Embeddable注解,则映射为@Embedded,
否则,如果属性对应的类型实现了Serializable, 则属性被映射为@Basic并在一个列中保存该对象的serialized版本,
否则,如果该属性的类型为java.sql.Clob或 java.sql.Blob,则作为@Lob并映射到适当的LobType.。
4. Hibernate 三种继承映射方式注解实现
hibernate应用中,继承的用途或目的主要有两点:
-
组件化:故明思义,把重复性的代码抽取成组件,以便重用和维护。hibernate应用中,一些重复的字段,重复的映射配置,就需要抽取成组件。
-
多态性:类的多态性是指下层业务所需一个父类对象,而上层业务根据所需的父类对象,传递一个子类对象。hibernate应用中,下层业务操作父类对象进行持久操作,如增删改查,上层业务则传递一个子类对象。
Hibernate 支持三种类型的继承形式
SINGLE_TABLE:将父类和及其子类存放在一张表中,并创建一个新的字段来判断对象的类型。TABLE_PER_CLASS:为父类及其每一个子类各创建一个表,这些表是相互独立的。JOINED:每个子类对应一张表,并与主类(父类)共享主表
1. SINGLE_TABLE

使用 SINGLE_TABLE 需要在父类添加
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
添加标识字段并为本类添加标识字段的值
@DiscriminatorColumn(name = "type",discriminatorType = DiscriminatorType.STRING)
@DiscriminatorValue("Person")
然后在不同的子类中设置不同的标识值,在Student子类中设置标识值
@DiscriminatorValue("Student")
在Teacher子类中设置标识值
@DiscriminatorValue("Teacher")
2. TABLE_PER_CLASS
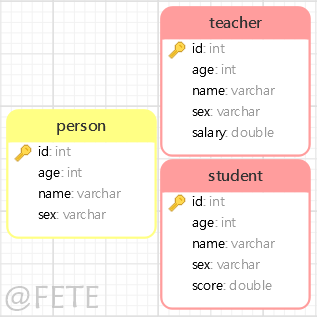
使用 TABLE_PER_CLASS 只需要在父类设置以下注解即可
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
但是,注解的主键生成策略不能使用GenerationType.IDENTITY,可以使用AUTO或其它。
3. JOINED
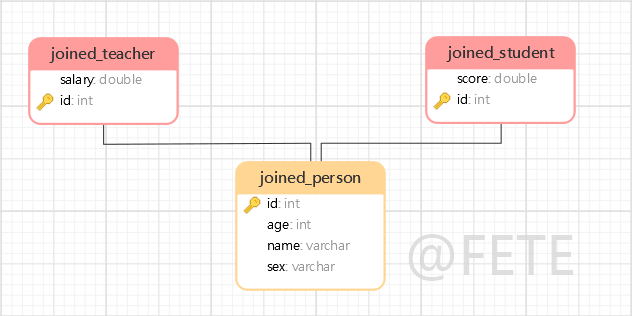
使用 JOINED 只需要在父类设置以下注解即可
@Inheritance(strategy = InheritanceType.JOINED)
可以在子类中设置共享主键的名称
@PrimaryKeyJoinColumn(name = "共享主键的名称")
如不设置,默认的主键名称与父类一致。
欢迎转载,转载请注明出处:https://blog.kaguramea.me/archives/hibernate-learning-note
